 W
WA computer cluster is a set of loosely or tightly connected computers that work together so that, in many aspects, they can be viewed as a single system. Unlike grid computers, computer clusters have each node set to perform the same task, controlled and scheduled by software.
 W
WFencing is the process of isolating a node of a computer cluster or protecting shared resources when a node appears to be malfunctioning.
 W
WThe history of computer clusters is best captured by a footnote in Greg Pfister's In Search of Clusters: “Virtually every press release from DEC mentioning clusters says ‘DEC, who invented clusters...’. IBM did not invent them either. Customers invented clusters, as soon as they could not fit all their work on one computer, or needed a backup. The date of the first is unknown, but it would be surprising if it was not in the 1960s, or even late 1950s.”
 W
WAn Aiyara cluster is a low-powered computer cluster specially designed to process Big Data. The Aiyara cluster model can be considered as a specialization of the Beowulf cluster in the sense that Aiyara is also built from commodity hardware, not inexpensive personal computers, but system-on-chip computer boards. Unlike Beowulf, applications of an Aiyara cluster are scoped only for the Big Data area, not for scientific high-performance computing. Another important property of an Aiyara cluster is that it is low-power. It must be built with a class of processing units that produces less heat.
 W
WASCI White was a supercomputer at the Lawrence Livermore National Laboratory in California, which was briefly the fastest supercomputer in the world.
Apache Beam is an open source unified programming model to define and execute data processing pipelines, including ETL, batch and stream (continuous) processing. Beam Pipelines are defined using one of the provided SDKs and executed in one of the Beam’s supported runners including Apache Flink, Apache Samza, Apache Spark, and Google Cloud Dataflow.
 W
WA Beowulf cluster is a computer cluster of what are normally identical, commodity-grade computers networked into a small local area network with libraries and programs installed which allow processing to be shared among them. The result is a high-performance parallel computing cluster from inexpensive personal computer hardware.
 W
WCHAOS is a small Linux distribution designed for creating ad hoc computer clusters. CHAOS is a Live CD which fits on a single business-card-sized CD-ROM. This tiny disc will boot any I586 class PC into a working OpenMosix node, without disturbing or touching the contents of any local hard disk.
 W
WCluster Computing: the Journal of Networks, Software Tools and Applications is a peer-reviewed scientific journal on parallel processing, distributed computing systems, and computer communication networks. The journal was established in 1998, and in 2016, the journal had a Journal Citation Reports impact factor of 2.040.
BeeGFS is a parallel file system, developed and optimized for high-performance computing. BeeGFS includes a distributed metadata architecture for scalability and flexibility reasons. Its most important aspect is data throughput.
 W
WFinisterrae was the 100th supercomputer in Top500 ranking in November 2007. Running at 12.97 teraFLOPS, it would rank at position 258 on the list as of June 2008. It is also the third most powerful supercomputer in Spain. It is located in Galicia.
 W
WA GPU cluster is a computer cluster in which each node is equipped with a Graphics Processing Unit (GPU). By harnessing the computational power of modern GPUs via General-Purpose Computing on Graphics Processing Units (GPGPU), very fast calculations can be performed with a GPU cluster.
 W
WGremlin is a graph traversal language and virtual machine developed by Apache TinkerPop of the Apache Software Foundation. Gremlin works for both OLTP-based graph databases as well as OLAP-based graph processors. Gremlin's automata and functional language foundation enable Gremlin to naturally support imperative and declarative querying, host language agnosticism, user-defined domain specific languages, an extensible compiler/optimizer, single- and multi-machine execution models, hybrid depth- and breadth-first evaluation, as well as Turing Completeness.
 W
WHPCx was a supercomputer located at the Daresbury Laboratory in Cheshire, England. The supercomputer was maintained by the HPCx Consortium, UoE HPCX Ltd, which was led by the University of Edinburgh: EPCC, with the Science and Technology Facilities Council and IBM. The project was funded by EPSRC.
 W
WIamus is a computer cluster located at Universidad de Málaga. Powered by Melomics' technology, the composing module of Iamus takes 8 minutes to create a full composition in different musical formats, although the native representation can be obtained by the whole system in less than a second. Iamus only composes full pieces of contemporary classical music.
 W
WMelomics109 is a computer cluster located at Universidad de Málaga. It is part of the Spanish Supercomputing Network, and has been designed to increase the computational power provided by Iamus. Powered by Melomics' technology, the composing module of Melomics109 is able to create and synthesize music in a variety of musical styles. This music has been made freely accessible to everyone.
WMessage passing is an inherent element of all computer clusters. All computer clusters, ranging from homemade Beowulfs to some of the fastest supercomputers in the world, rely on message passing to coordinate the activities of the many nodes they encompass. Message passing in computer clusters built with commodity servers and switches is used by virtually every internet service.
 W
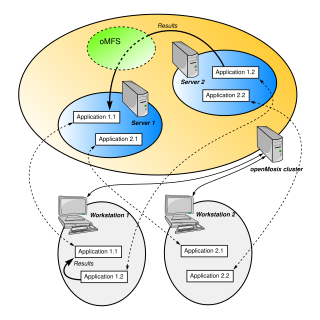
WopenMosix is a free cluster management system that provided single-system image (SSI) capabilities, e.g. automatic work distribution among nodes. It allowed program processes to migrate to machines in the node's network that would be able to run that process faster. It was particularly useful for running parallel applications having low to moderate input/output (I/O). It was released as a Linux kernel patch, but was also available on specialized Live CDs. openMosix development has been halted by its developers, but the LinuxPMI project is continuing development of the former openMosix code.
OpenVMS is a multi-user, multiprocessing virtual memory-based operating system designed for use in time-sharing, batch processing, and transaction processing. It was first released by Digital Equipment Corporation in 1977 as VAX/VMS for its series of VAX minicomputers. Since 2014 OpenVMS is developed and supported by a company named VMS Software Inc. (VSI).
 W
WA server farm or server cluster is a collection of computer servers – usually maintained by an organization to supply server functionality far beyond the capability of a single machine. Server farms often consist of thousands of computers which require a large amount of power to run and to keep cool. At the optimum performance level, a server farm has enormous costs associated with it. Server farms often have backup servers, which can take over the function of primary servers in the event of a primary-server failure. Server farms are typically collocated with the network switches and/or routers which enable communication between the different parts of the cluster and the users of the cluster. Server farmers typically mount the computers, routers, power supplies, and related electronics on 19-inch racks in a server room or data center.
The Slurm Workload Manager, formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world's supercomputers and computer clusters.
 W
WOracle Solaris Cluster is a high-availability cluster software product for Solaris, originally created by Sun Microsystems, which was acquired by Oracle Corporation in 2010. It is used to improve the availability of software services such as databases, file sharing on a network, electronic commerce websites, or other applications. Sun Cluster operates by having redundant computers or nodes where one or more computers continue to provide service if another fails. Nodes may be located in the same data center or on different continents.
 W
WSpace-based architecture (SBA) is a distributed-computing architecture for achieving linear scalability of stateful, high-performance applications using the tuple space paradigm. It follows many of the principles of representational state transfer (REST), service-oriented architecture (SOA) and event-driven architecture (EDA), as well as elements of grid computing. With a space-based architecture, applications are built out of a set of self-sufficient units, known as processing-units (PU). These units are independent of each other, so that the application can scale by adding more units. The SBA model is closely related to other patterns that have been proved successful in addressing the application scalability challenge, such as shared nothing architecture (SN), used by Google, Amazon.com and other well-known companies. The model has also been applied by many firms in the securities industry for implementing scalable electronic securities trading applications.
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Spark provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.
 W
WA supercomputer is a computer with a high level of performance as compared to a general-purpose computer. The performance of a supercomputer is commonly measured in floating-point operations per second (FLOPS) instead of million instructions per second (MIPS). Since 2017, there are supercomputers which can perform over 1017 FLOPS (a hundred quadrillion FLOPS, 100 petaFLOPS or 100 PFLOPS). Since November 2017, all of the world's fastest 500 supercomputers run Linux-based operating systems. Additional research is being conducted in the United States, the European Union, Taiwan, Japan, and China to build faster, more powerful and technologically superior exascale supercomputers.
Univa is a software company that develops workload management and cloud management products for compute-intensive applications in the data center and across public, private, and hybrid clouds.
 W
WUnited Devices, Inc. was a privately held, commercial distributed computing company that focused on the use of grid computing to manage high-performance computing systems and enterprise cluster management. Its products and services allowed users to "allocate workloads to computers and devices throughout enterprises, aggregating computing power that would normally go unused." It operated under the name Univa UD for a time, after merging with Univa on September 17, 2007.
Xgrid is a proprietary program and distributed computing protocol developed by the Advanced Computation Group subdivision of Apple Inc that allows networked computers to contribute to a single task.