 W
WIn computer engineering, computer architecture is a set of rules and methods that describe the functionality, organization, and implementation of computer systems. Some definitions of architecture define it as describing the capabilities and programming model of a computer but not a particular implementation. In other definitions computer architecture involves instruction set architecture design, microarchitecture design, logic design, and implementation.
 W
WIn computing, an arithmetic logic unit (ALU) is a combinational digital circuit that performs arithmetic and bitwise operations on integer binary numbers. This is in contrast to a floating-point unit (FPU), which operates on floating point numbers. It is a fundamental building block of many types of computing circuits, including the central processing unit (CPU) of computers, FPUs, and graphics processing units (GPUs).
 W
WAn autonomous decentralized system is a decentralized system composed of modules or components that are designed to operate independently but are capable of interacting with each other to meet the overall goal of the system. This design paradigm enables the system to continue to function in the event of component failures. It also enables maintenance and repair to be carried out while the system remains operational. Autonomous decentralized systems have a number of applications including industrial production lines, railway signalling and robotics.
 W
WIn computing, a cache is a hardware or software component that stores data so that future requests for that data can be served faster; the data stored in a cache might be the result of an earlier computation or a copy of data stored elsewhere. A cache hit occurs when the requested data can be found in a cache, while a cache miss occurs when it cannot. Cache hits are served by reading data from the cache, which is faster than recomputing a result or reading from a slower data store; thus, the more requests that can be served from the cache, the faster the system performs.
 W
WCache hierarchy, or multi-level caches, refers to a memory architecture that uses a hierarchy of memory stores based on varying access speeds to cache data. Highly-requested data is cached in high-speed access memory stores, allowing swifter access by central processing unit (CPU) cores.
 W
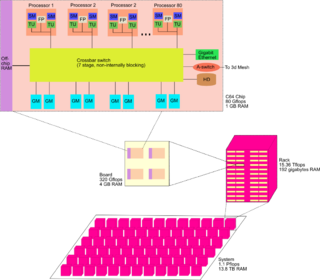
WA cellular architecture is a type of computer architecture prominent in parallel computing. Cellular architectures are relatively new, with IBM's Cell microprocessor being the first one to reach the market. Cellular architecture takes multi-core architecture design to its logical conclusion, by giving the programmer the ability to run large numbers of concurrent threads within a single processor. Each 'cell' is a compute node containing thread units, memory, and communication. Speed-up is achieved by exploiting thread-level parallelism inherent in many applications.
 W
WComputer data storage is a technology consisting of computer components and recording media that are used to retain digital data. It is a core function and fundamental component of computers.
 W
WThe Harvard architecture is a computer architecture with separate storage and signal pathways for instructions and data. It contrasts with the von Neumann architecture, where program instructions and data share the same memory and pathways.
 W
WIn computer architecture, the memory hierarchy separates computer storage into a hierarchy based on response time. Since response time, complexity, and capacity are related, the levels may also be distinguished by their performance and controlling technologies. Memory hierarchy affects performance in computer architectural design, algorithm predictions, and lower level programming constructs involving locality of reference.
 W
WMemory management is a form of resource management applied to computer memory. The essential requirement of memory management is to provide ways to dynamically allocate portions of memory to programs at their request, and free it for reuse when no longer needed. This is critical to any advanced computer system where more than a single process might be underway at any time.
 W
WA multi-core processor is a computer processor on a single integrated circuit with two or more separate processing units, called cores, each of which reads and executes program instructions. The instructions are ordinary CPU instructions but the single processor can run instructions on separate cores at the same time, increasing overall speed for programs that support multithreading or other parallel computing techniques. Manufacturers typically integrate the cores onto a single integrated circuit die or onto multiple dies in a single chip package. The microprocessors currently used in almost all personal computers are multi-core.
 W
WRandom-access memory is a form of computer memory that can be read and changed in any order, typically used to store working data and machine code. A random-access memory device allows data items to be read or written in almost the same amount of time irrespective of the physical location of data inside the memory. In contrast, with other direct-access data storage media such as hard disks, CD-RWs, DVD-RWs and the older magnetic tapes and drum memory, the time required to read and write data items varies significantly depending on their physical locations on the recording medium, due to mechanical limitations such as media rotation speeds and arm movement.
 W
WIn computer science, shared memory is memory that may be simultaneously accessed by multiple programs with an intent to provide communication among them or avoid redundant copies. Shared memory is an efficient means of passing data between programs. Depending on context, programs may run on a single processor or on multiple separate processors.
 W
WSpiNNaker is a massively parallel, manycore supercomputer architecture designed by the Advanced Processor Technologies Research Group (APT) at the Department of Computer Science, University of Manchester. It is composed of 57,600 processing nodes, each with 18 ARM9 processors and 128 MB of mobile DDR SDRAM, totalling 1,036,800 cores and over 7 TB of RAM. The computing platform is based on spiking neural networks, useful in simulating the human brain.
 W
WA superscalar processor is a CPU that implements a form of parallelism called instruction-level parallelism within a single processor. In contrast to a scalar processor that can execute at most one single instruction per clock cycle, a superscalar processor can execute more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to different execution units on the processor. It therefore allows for more throughput than would otherwise be possible at a given clock rate. Each execution unit is not a separate processor, but an execution resource within a single CPU such as an arithmetic logic unit.
 W
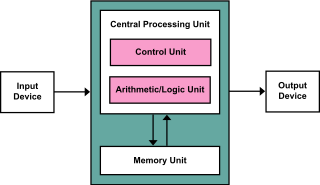
WThe von Neumann architecture—also known as the von Neumann model or Princeton architecture—is a computer architecture based on a 1945 description by John von Neumann and others in the First Draft of a Report on the EDVAC. That document describes a design architecture for an electronic digital computer with these components:A processing unit that contains an arithmetic logic unit and processor registers A control unit that contains an instruction register and program counter Memory that stores data and instructions External mass storage Input and output mechanisms