 W
WAnalogy is a cognitive process of transferring information or meaning from a particular subject to another, or a linguistic expression corresponding to such a process. In a narrower sense, analogy is an inference or an argument from one particular to another particular, as opposed to deduction, induction, and abduction, in which at least one of the premises, or the conclusion, is general rather than particular in nature. The term analogy can also refer to the relation between the source and the target themselves, which is often a similarity, as in the biological notion of analogy.
 W
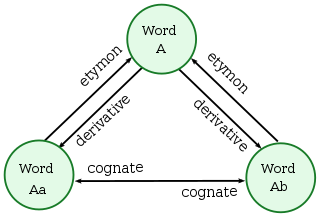
WIn linguistics, cognates, also called lexical cognates, are words that have a common etymological origin. Cognates are often inherited from a shared parent language, but they may also involve borrowings from some other language. For example, the English words dish, disk and desk, the German word Tisch ("table"), and the Latin word discus ("disk") are cognates because they all come from Ancient Greek δίσκος, which relates to their flat surfaces. Cognates may have evolved similar, different or even opposite meanings, and although there are usually some similar sounds or letters in the words, they may appear to be dissimilar. Some words sound similar, but do not come from the same root; these are called false cognates, while some are truly cognate but differ in meaning; these are called false friends.
 W
WIn corpus linguistics, a collocation is a series of words or terms that co-occur more often than would be expected by chance. In phraseology, a collocation is a type of compositional phraseme, meaning that it can be understood from the words that make it up. This contrasts with an idiom, where the meaning of the whole cannot be inferred from its parts, and may be completely unrelated.
 W
WFamily resemblance is a philosophical idea made popular by Ludwig Wittgenstein, with the best known exposition given in his posthumously published book Philosophical Investigations (1953). It argues that things which could be thought to be connected by one essential common feature may in fact be connected by a series of overlapping similarities, where no one feature is common to all of the things. Games, which Wittgenstein used as an example to explain the notion, have become the paradigmatic example of a group that is related by family resemblances. It has been suggested that Wittgenstein picked up the idea and the term from Friedrich Nietzsche, who had been using it, as did many nineteenth century philologists, when discussing language families.
 W
WA homophone is a word that is pronounced the same as another word but differs in meaning. A homophone may also differ in spelling. The two words may be spelled the same, a for example rose (flower) and rose, or differently, as in rain, reign, and rein. The term "homophone" may also apply to units longer or shorter than words, for example a phrase, letter, or groups of letters which are pronounced the same as another phrase, letter, or group of letters. Any unit with this property is said to be "homophonous".
 W
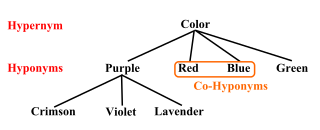
WIn linguistics, hyponymy is a semantic relation between a hyponym denoting a subtype and a hypernym or hyperonym denoting a supertype. In other words, the semantic field of the hyponym is included within that of the hypernym. In simpler terms, a hyponym is in a type-of relationship with its hypernym. For example: pigeon, crow, eagle, and seagull are all hyponyms of bird, their hypernym; which itself is a hyponym of animal, its hypernym.
 W
WA semantic network, or frame network is a knowledge base that represents semantic relations between concepts in a network. This is often used as a form of knowledge representation. It is a directed or undirected graph consisting of vertices, which represent concepts, and edges, which represent semantic relations between concepts, mapping or connecting semantic fields. A semantic network may be instantiated as, for example, a graph database or a concept map.
 W
WA synonym is a word, morpheme, or phrase that means exactly or nearly the same as another word, morpheme, or phrase in a given language. For example, in the English language, the words begin, start, commence, and initiate are all synonyms of one another: they are synonymous. The standard test for synonymy is substitution: one form can be replaced by another in a sentence without changing its meaning. Words are considered synonymous in only one particular sense: for example, long and extended in the context long time or extended time are synonymous, but long cannot be used in the phrase extended family. Synonyms with exactly the same meaning share a seme or denotational sememe, whereas those with inexactly similar meanings share a broader denotational or connotational sememe and thus overlap within a semantic field. The former are sometimes called cognitive synonyms and the latter, near-synonyms, plesionyms or poecilonyms.
 W
WA topic map is a standard for the representation and interchange of knowledge, with an emphasis on the findability of information. Topic maps were originally developed in the late 1990s as a way to represent back-of-the-book index structures so that multiple indexes from different sources could be merged. However, the developers quickly realized that with a little additional generalization, they could create a meta-model with potentially far wider application. The ISO standard is formally known as ISO/IEC 13250:2003.
 W
WIn natural language processing (NLP), word embedding is a term used for the representation of words for text analysis, typically in the form of a real-valued vector that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning. Word embeddings can be obtained using a set of language modeling and feature learning techniques where words or phrases from the vocabulary are mapped to vectors of real numbers. Conceptually it involves the mathematical embedding from space with many dimensions per word to a continuous vector space with a much lower dimension.
 W
WWord ladder is a word game invented by Lewis Carroll. A word ladder puzzle begins with two words, and to solve the puzzle one must find a chain of other words to link the two, in which two adjacent words differ by one letter.
WWord2vec is a technique for natural language processing published in 2013. The word2vec algorithm uses a neural network model to learn word associations from a large corpus of text. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. As the name implies, word2vec represents each distinct word with a particular list of numbers called a vector. The vectors are chosen carefully such that a simple mathematical function indicates the level of semantic similarity between the words represented by those vectors.